SEO に関連する記事 => 誰にもでGoogle Sitemapサービスを > 7. URLリストの再取得(初回限定)
初めてプロジェクトをセットアップする場合、設定した内容で正しくURLが取得されたか慎重に確認する必要があります。このURLリストテーブルをベースに今後のメンテナンスを行う事になるからです。
意図したとおりにURLリストテーブルが取得できなかった場合は、このページで示す方法で一度テーブルを削除して、再度、Crawel を実行するようにして下さい。これらの作業が必要になるのは、初回プロジェクト作成時のみです。
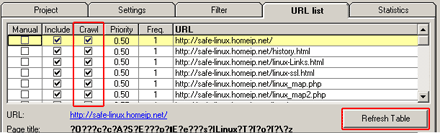
先ほどのステップで GSiteCrawler がクロールにより取得した URL リストテーブルを確認します。Refresh table ボタンを押し、テーブルを表示します。設定した通り、正しくURLを収集できているか確認してください。重要なチェックポイントは、以下の二点です。
深重にチェックしてください。
リンク階層が深すぎて全てのURLが取得されていない場合は、もう一度 (Re)Crawl を実行します。この場合は、リストを削除する必要はありません。
今度は、Crawl にチェックの入っているURL を基点にクロールしますので、正しくリンクされていれば、前回取得できなかったURLを取得しリストに追加される筈です。
クロール完了後、Refresh Table を実行する必要があります。
もし、取得されないのであれば、リンク構造を見直した方が良いかもしれません。余程のことでない限りこのような事はないと思いますが。
どの URL に自動的に Crawl のチェックを入れるかは、File extentions to check.[not to follow] で設定出来ます。
初回の Crawl で意図したURL リストテーブルが作成されなかった場合、再度、Setting タブ内の設定を修整する必要があります。
この場合、URLリストテーブルに変更箇所のURLが追加されるだけなので、変更のあったURLが追加され問題のURLと重複します。手動でURLリストテーブルを手動で修正しても構いませんが、ページ数が多いと必ず見落とします。
一度、URLリストテーブルを削除して、再度 (Re)Crawl を実行し、新しくURLリストテーブルを作成する必要があります。特に、最初のプロジェクト作成時はベースとなるURLリストテーブルは完璧にしておく必要があります。
取得したURLリストテーブルを削除するには Delete all non-manual list ボタンを押します。これは、manual にチェックの入っていないURLリストを全て削除します。

URLリストテーブルの manual のチェックは、自分で追加したURLの事で、Crawler が取得したURLなのか、自分で設定したURLなのか識別するための項目です。このチェックは、出力する XMLサイトマップには何ら影響を与えるものではありません。
全てのテーブルが削除できたら、再度
を実行してください。意図したとおりにURLリストテーブルが作成できるまで、この一連の作業を繰り返します。
万事、意図したとおりにURLリストテーブルが作成できたら、次はこのURLリストテーブルを使用して、URL毎の重要性の相対関係を設定していきます。
(Re)Crawl では、URLリストを更新、又は新たに見つけたURLを追加していくという動作となります。ここで取得したURLリストテーブルをベースに (Re)Crawl を繰り返すことで、URLの更新日取得、追加されたURLをこのテーブルに追加するという事に注意して下さい。

