STEP 4 ウィザード終了後に実行する項目 ~ GSiteCrawler
STEP 4 ウィザードによるセットアップ
ウィザード実行後に行う処理を設定します。
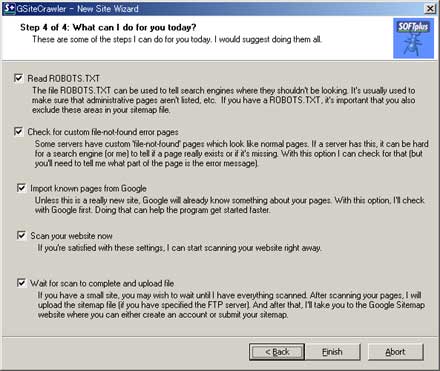
- Read ROBOTS.TXT
- ここにチェックを入れると、 robot.txt ファイルでクロール制御を行っている場合、robot.txt に定義されているURLを除外します。(公開ディレクトリに設置されている robot.txtを参照します) robot.txt を用いてクローラーの制限を行っている場合はチェックを入れて下さい。
- Check for custom file-not-found error pages
- サーバーレスポンスの file-not-found error ではなく、特定のURLページを表示するように設定されているサーバーの場合、GSiteCrawler は、そのページは存在すると解釈してしまいます。
- file-not-found error を検出するためには、ここにチェックを入れそのURLは、file-not-found error を示していることを GSiteCrawler に教える必要があります。
- このエラーの際、サーバーが返す特定のURLページを指定するには、ウィザード終了後、 Settings タブ → General タブの
HTML Code/Text on a custom 404-Error Page ["file not found"]
で該当する URLを指定し、再度、(Re)Crawl を行う必要があります。
- Import known pages from Google
- google に既にインデックス(登録)されているページを問い合わせ、既にインデックスされたURL(ページ)を基準に Crawl し URL を取得します。サイトを立ち上げたばかりで、一つも Google にインデックス(検索対象)になっていない場合は、URLリストを取得する事は出来ません。また、GSiteCrawler の Global オプションでエージェントを googlebot に変更していた場合も取得することは出来ません。
- この状況下で試した訳ではありませんが、この場合、ウィザード終了後、上部メニューの Importから、サーバ ログ、サイトマップ、URLテキスト、ローカルファイルの何れかからURLを取得する必要があります。
- 参照 => Google Sitemap に必要な URL を取得する(クロール実行)
- Scan your website now
- このウィザードで設定した内容で、Webサイトをスキャンします。初回はチェックを入れます。その結果をみてフィルタを設定した方がいいでしょう。リンクを辿りURLを取得しますので、サイトの規模によっては全てのURL取得に時間がかかります。リアルタイムにクロールの状況を確認するには、上部メニューのShow ボタンを押します。

- 処理中は、画面左下に Crawlers busy と表示されています。終了すると Crawlers idle に
変わります。進行状況をリアルタイムで確認するには、メニューバーの Show をクリックします。
- Wait for scan to complete and upload file
- ここにチェックを入れると、FTPで指定したサーバーにサイトマップファイルをアップロードします。アップロード後、Google にサイトマップを申請するために、Google Sitemap ページへ接続します。
- ここでは、作成する内容を確認後、アップロードする手順を、チェックを外します。
ウィザード終了後の設定については、手動セットアップを参照して下さい。

