SEO に関連する記事 => 誰にもでGoogle Sitemapサービスを > 6. URLリストを取得する
これまでのセッティング、フィルター設定が出来ましたら、URLリストを取得するためにGSiteCrawler にサイトを巡回していもらいます。この作業により、Google sitemap.xml の元となる URLリストテーブルが作成される事になります。
URL を取得、つまり、GSiteCrawler がサイトを巡回するには、基点となるURLどうするかで、いくつかの方法が用意されています。
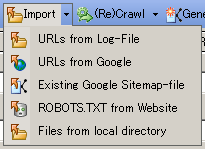
上記の Import は行わず、 上部メニューの (Re)Crawl を実行します。
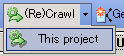
この場合、Project タブ で設定した Main URL (1URL-ここではサイトトップ)を基準に Crawl を開始します。
(Re)Crawl実行すると画面下が idle から busy 状態に変わります。

サイトの規模やリンク構造、Webサーバーによっては Crawl が終了するまでかなり時間がかかります。このサイトで3~5分ほどです。何匹の Crawler でサイトを巡回するかは File → Global options で行えます。
巡回する Crawler の数が多いと、Webサーバーに高い負荷を掛けてしまい逆にサーバーレスポンスが低下します。デフォルトの 6 が推奨です。 また、DNS/Webサーバーによってはタイムアウト時間を適切に設定しないエラーになる場合もあります。この場合も File → Global options でチューニングする必要があるかもしれません。
![]()
上部メニューの Show ボタンをクリックすると GSiteCrawler が現在行っているクロール状況をリアルタイムで確認する事が出来ます。(デフォルトでは5秒置きの更新)
Crawl が終了するとそれを知らせるカウントダウン付きのアラート画面が表示され
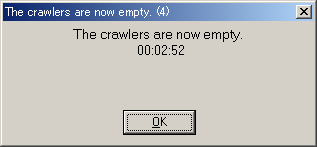
待機状態に変わります。

URLリストテーブルを確認し、意図したとおりにリストされているか確認してください。URLリストテーブルの見方については、以下で説明しています。
参照 => 取得した URL リストをカスタマイズする(SEO最適化)
取得したURL リストテーブルの確認を行います。問題があった場合は、再度設定を見直し、URLリストテーブルを削除する必要があります。次は、再度、URLリストテーブルを作成する場合の注意点について説明します。

