Filter タブでは、GSiteCrawler がURL取得のために行う Crawl の動作を制御する事ができます。(特定の文字列を含むURL、或いはURL を巡回しないなど)
ここでは、GSiteCrawler が URL を収集する際の Crawl 動作に関する動作を制限します。これにより、Crawl すべき URL を絞り込む事が出来るため、クロールも早く終了させる事も出来ます。
画像ファイルなど指定すれば、URLリストテーブルにも取り込まれないため、URLリストテーブルを使ったカスタマイズも容易になります。
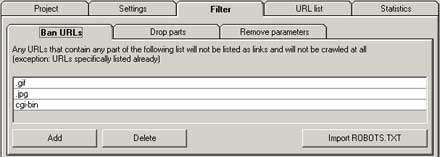
GSiteCrawler にクロールを禁止するURLの一部、又はURLを記述します。これによりURLリストには追加されなくなり、GSiteCrawler がクロールにより収集するアドレスも減少するためクロールも早く終了します。
画像を Crawl 対象にしたくない場合は、拡張子、つまり URL の語尾を記述すれば良い事になります。
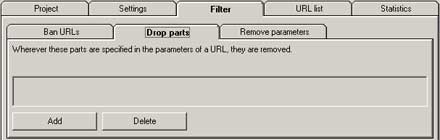
除外したいパラメーターがURLに含まれる場合、その文字列を取り除いてURLとしてクロールを試みます。もし、接続できなければ、Statistics タブ → Aborted URLs にリンクエラーとしてレポートされます。
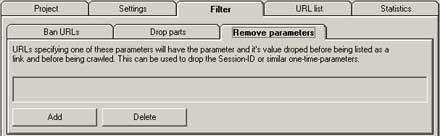
URLにセッションID や SID が含まれる場合、URLからこれらのパラメーターを除外します。これらが含まれる文字列を指定する事で、URLから削除し、結果クロール出来ない状態にするのだと思います。(未確認)
アクセス出来ない場合はエラーが、Statistics タブ → Aborted URLs に記録されると思うので要確認です。
そもそもこのようなアドレスがクロール可能な状態である事がセキュリティ上問題なので、ここで除外するのではなく、このようなリンク自体存在すべきでありません。
例えば、以下のようなURLです。
http://www.sample.net/usr/login.php?sid=3bga5d3yhd9sa22af3g46a
注意
ここまでの設定を変更した場合、前回取得したURLリストは、一度削除する必要があります。重複するURLが追加されるからです。手動でURLリストを修整しても構いませんが、全てを削除してから再度、クロールを行う方が確実です。
取得したURLリストテーブルの削除方法は後述します。

